Code
library(tidyverse)
library(ggplot2)
library(tidymodels)
library(rsample)
library(tidyverse)
library(ggplot2)
library(tidymodels)
library(rsample)from https://www.kaggle.com/c/titanic/data
pred <- c("Pclass", "Sex", "Age", "SibSp", "Parch", "Embarked", "title")
train_df_raw <- read_csv('data/train.csv')
test_df_raw <- read_csv('data/test.csv')
glimpse(train_df_raw)Rows: 891
Columns: 12
$ PassengerId <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
$ Survived <dbl> 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1…
$ Pclass <dbl> 3, 1, 3, 1, 3, 3, 1, 3, 3, 2, 3, 1, 3, 3, 3, 2, 3, 2, 3, 3…
$ Name <chr> "Braund, Mr. Owen Harris", "Cumings, Mrs. John Bradley (Fl…
$ Sex <chr> "male", "female", "female", "female", "male", "male", "mal…
$ Age <dbl> 22, 38, 26, 35, 35, NA, 54, 2, 27, 14, 4, 58, 20, 39, 14, …
$ SibSp <dbl> 1, 1, 0, 1, 0, 0, 0, 3, 0, 1, 1, 0, 0, 1, 0, 0, 4, 0, 1, 0…
$ Parch <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 1, 0, 0, 5, 0, 0, 1, 0, 0, 0…
$ Ticket <chr> "A/5 21171", "PC 17599", "STON/O2. 3101282", "113803", "37…
$ Fare <dbl> 7.2500, 71.2833, 7.9250, 53.1000, 8.0500, 8.4583, 51.8625,…
$ Cabin <chr> NA, "C85", NA, "C123", NA, NA, "E46", NA, NA, NA, "G6", "C…
$ Embarked <chr> "S", "C", "S", "S", "S", "Q", "S", "S", "S", "C", "S", "S"…train_df=train_df_raw %>%
mutate(Survived=as.factor(Survived),
title = str_trim(str_replace(str_extract(Name, ", [A-Z]+[A-Za-z.]*[:space:]+"), ",", ""))
)
dim(train_df)[1] 891 13train_df %>% count(Survived)# A tibble: 2 × 2
Survived n
<fct> <int>
1 0 549
2 1 342342/(549+342)[1] 0.3838384test_df=test_df_raw %>%
mutate(
title = str_trim(str_replace(str_extract(Name, ", [A-Z]+[A-Za-z.]*[:space:]+"), ",", ""))
)
dim(test_df)[1] 418 12data_split <- initial_split(data=train_df, prop = 0.6)model_data_train=training(data_split) model_data_test=testing(data_split) # declare recipe
titanic_recipe <-
recipe(Survived ~ Pclass + Sex + Age + SibSp + Parch + Fare + Embarked,
data = data_split) %>% # keep variables we want
step_impute_median(Age,Fare) %>% # imputation
step_impute_mode(Embarked) %>% # imputation
step_mutate_at( Pclass, Sex, Embarked, fn = factor) %>% # make these factors
step_mutate(Travelers = SibSp + Parch + 1) %>% # new variable
step_rm(SibSp, Parch) %>% # remove variables
step_dummy(all_nominal_predictors()) %>% # create indicator variables
# normalize numerical variables
step_normalize(all_numeric_predictors())
summary(titanic_recipe)# A tibble: 8 × 4
variable type role source
<chr> <list> <chr> <chr>
1 Pclass <chr [2]> predictor original
2 Sex <chr [3]> predictor original
3 Age <chr [2]> predictor original
4 SibSp <chr [2]> predictor original
5 Parch <chr [2]> predictor original
6 Fare <chr [2]> predictor original
7 Embarked <chr [3]> predictor original
8 Survived <chr [3]> outcome originaltitanic_recipe_prep=titanic_recipe %>% prep()train_proc <- bake(titanic_recipe_prep, new_data = model_data_train)test_proc <- bake(titanic_recipe_prep, new_data = model_data_test)fianl_submissions_proc <- bake(titanic_recipe_prep, new_data = test_df)juice(xxx) is same as bake(pre_recipe,new_data)
glimpse(test_proc)Rows: 357
Columns: 9
$ Age <dbl> -0.55659448, 0.68473761, 0.45198784, -0.71176099, 2.0036529…
$ Fare <dbl> -0.50565484, 0.73711309, 0.38420886, -0.49012832, -0.335833…
$ Survived <fct> 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0,…
$ Travelers <dbl> 0.01174777, 0.01174777, 0.01174777, -0.55855325, -0.5585532…
$ Pclass_X2 <dbl> -0.4971919, -0.4971919, -0.4971919, -0.4971919, 2.0075295, …
$ Pclass_X3 <dbl> 0.8857095, -1.1269240, -1.1269240, 0.8857095, -1.1269240, 0…
$ Sex_male <dbl> 0.7034699, -1.4188630, -1.4188630, 0.7034699, -1.4188630, 0…
$ Embarked_Q <dbl> -0.3103683, -0.3103683, -0.3103683, -0.3103683, -0.3103683,…
$ Embarked_S <dbl> 0.601304, -1.659938, 0.601304, 0.601304, 0.601304, -1.65993…glimpse(fianl_submissions_proc)Rows: 418
Columns: 8
$ Age <dbl> 0.41319622, 1.38298691, 2.54673575, -0.16867820, -0.5565944…
$ Fare <dbl> -0.49441364, -0.51050688, -0.45834747, -0.47824083, -0.4078…
$ Travelers <dbl> -0.55855325, 0.01174777, -0.55855325, -0.55855325, 0.582048…
$ Pclass_X2 <dbl> -0.4971919, -0.4971919, 2.0075295, -0.4971919, -0.4971919, …
$ Pclass_X3 <dbl> 0.8857095, 0.8857095, -1.1269240, 0.8857095, 0.8857095, 0.8…
$ Sex_male <dbl> 0.7034699, -1.4188630, 0.7034699, 0.7034699, -1.4188630, 0.…
$ Embarked_Q <dbl> 3.2159444, -0.3103683, 3.2159444, -0.3103683, -0.3103683, -…
$ Embarked_S <dbl> -1.659938, 0.601304, -1.659938, 0.601304, 0.601304, 0.60130…# logistic regression
titanic_logistic_spec <-
logistic_reg() %>% # model
set_engine('glm') %>% # package to use
set_mode('classification') # choose one of two: classification vs regressonif not using work flow then the data need to be baked data
no_workflow_fit <- titanic_logistic_spec %>%
fit(Survived ~ ., data = train_proc)
no_workflow_fitparsnip model object
Call: stats::glm(formula = Survived ~ ., family = stats::binomial,
data = data)
Coefficients:
(Intercept) Age Fare Travelers Pclass_X2 Pclass_X3
-0.6739 -0.5096 0.1234 -0.4108 -0.3702 -0.9458
Sex_male Embarked_Q Embarked_S
-1.2755 -0.1100 -0.1469
Degrees of Freedom: 533 Total (i.e. Null); 525 Residual
Null Deviance: 706.3
Residual Deviance: 486.3 AIC: 504.3#Workflow
model_workflow <-
workflow() %>%
add_recipe(titanic_recipe) %>%
add_model(titanic_logistic_spec)
model_workflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: logistic_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
7 Recipe Steps
• step_impute_median()
• step_impute_mode()
• step_mutate_at()
• step_mutate()
• step_rm()
• step_dummy()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
Logistic Regression Model Specification (classification)
Computational engine: glm training with train data. and the raw train data will auto flow through recipe with feature engineering
model_fit <-
model_workflow %>%
fit(train_df) model formulate
model_fit══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: logistic_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
7 Recipe Steps
• step_impute_median()
• step_impute_mode()
• step_mutate_at()
• step_mutate()
• step_rm()
• step_dummy()
• step_normalize()
── Model ───────────────────────────────────────────────────────────────────────
Call: stats::glm(formula = ..y ~ ., family = stats::binomial, data = data)
Coefficients:
(Intercept) Age Fare Travelers Pclass_X2 Pclass_X3
-0.64428 -0.49272 0.12599 -0.35432 -0.36258 -1.06025
Sex_male Embarked_Q Embarked_S
-1.30836 -0.02427 -0.20127
Degrees of Freedom: 890 Total (i.e. Null); 882 Residual
Null Deviance: 1187
Residual Deviance: 786.6 AIC: 804.6library(yardstick)
test_probs <-
predict(model_fit, model_data_test, type = "prob") %>%
bind_cols(model_data_test)
test_roc <-
test_probs %>%
roc_curve(Survived, .pred_0)
test_probs %>% roc_auc(Survived, .pred_0)# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc binary 0.875autoplot(test_roc) 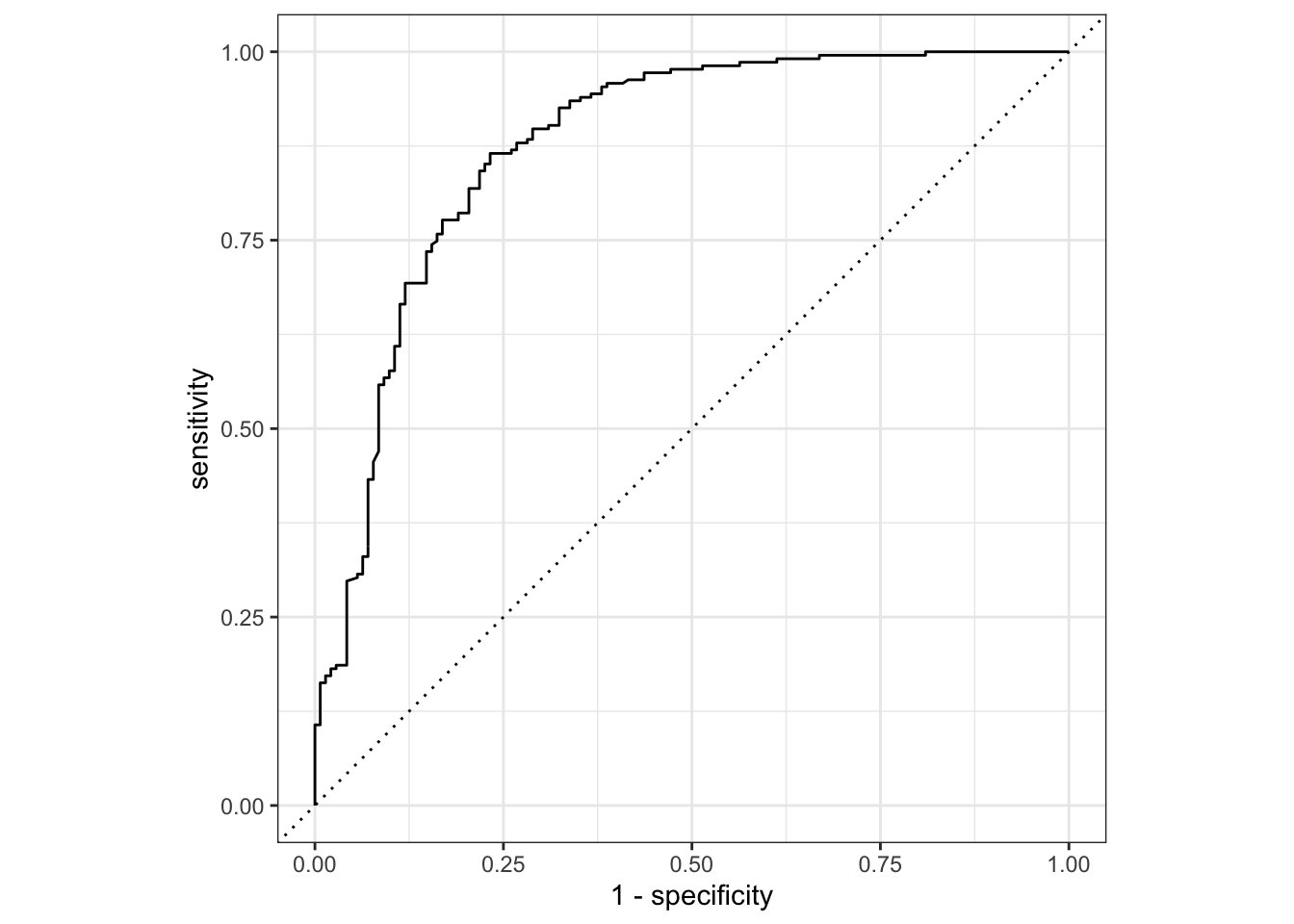
library(vip) # variable importance plots
model_fit %>%
extract_fit_parsnip() %>%
vip() +
labs(title = "What are the most important\nvariables?") 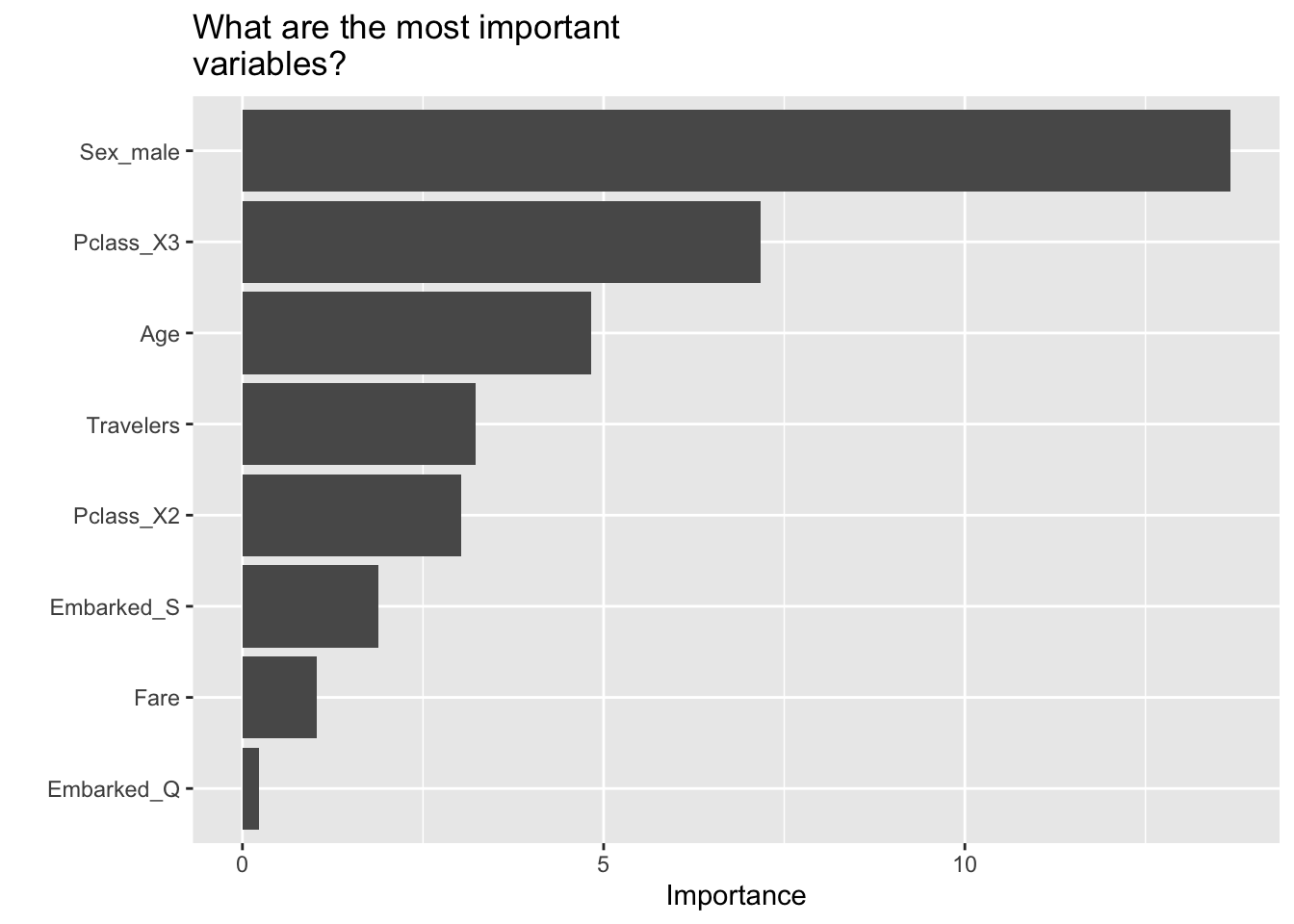
predict with final submission data. and the submission data will auto flow through recipe with feature engineering
##Prepare data for submission
pred <- predict(model_fit, new_data = test_df) %>%
bind_cols(test_df) %>%
mutate(Survived = .pred_class) %>%
select(PassengerId, Survived)
head(pred)# A tibble: 6 × 2
PassengerId Survived
<dbl> <fct>
1 892 0
2 893 0
3 894 0
4 895 0
5 896 1
6 897 0 if not using workflow then the predict data need to be baked
fianl_submissions_proc <- bake(titanic_recipe_prep, new_data = test_df)
pred <- predict(no_workflow_fit, new_data = fianl_submissions_proc) %>%
bind_cols(test_df) %>%
mutate(Survived = .pred_class) %>%
select(PassengerId, Survived)
head(pred)# A tibble: 6 × 2
PassengerId Survived
<dbl> <fct>
1 892 0
2 893 0
3 894 0
4 895 0
5 896 1
6 897 0 write.csv(pred, "result.csv", row.names = FALSE)https://www.kaggle.com/c/titanic/data
https://rpubs.com/tsadigov/titanic_tidymodels